Checklist Incident Priority

Definition: An Incident's priority is usually determined by assessing its impact and urgency: 'Urgency' is a measure how quickly a resolution of the Incident is required. 'Impact' is measure of the extent of the Incident and of the potential damage caused by the Incident before it can be resolved.
ITIL Process: ITIL Service Operation - Incident Management
ITIL 4 Practice: Incident management
Checklist Category: ITIL Templates
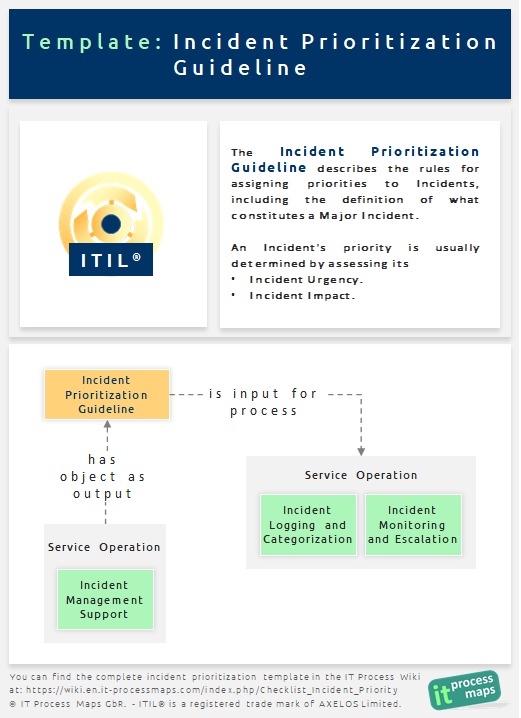
Incident Prioritization Guideline

The Incident Prioritization Guideline describes the rules for assigning 'priorities to Incidents', including the definition of what constitutes a 'Major Incident'. Since Incident Management escalation rules are usually based on priorities, assigning the correct priority to an Incident is essential for triggering appropriate 'Incident escalations'.
Incident Urgency (Categories of Urgency)
This section establishes categories of urgency. The definitions must suit the type of organization, so the following table is only an example:
To determine the Incident's urgency, choose the highest relevant category:
| Category | Description |
|---|---|
| High (H) |
|
| Medium (M) |
|
| Low (L) |
|
Incident Impact (Categories of Impact)
This section establishes categories of impact. The definitions must suit the type of organization, so the following table is only an example:
To determine the Incident's impact, choose the highest relevant category:
| Category | Description |
|---|---|
| High (H) |
|
| Medium (M) |
|
| Low (L) |
|
Incident Priority Classes
Incident Priority is derived from urgency and impact.
Incident Priority Matrix
If classes are defined to rate urgency and impact (see above), an Urgency-Impact Matrix (also referred to as Incident Priority Matrix) can be used to define priority classes, identified in this example by colors and priority codes:
| Impact | ||||
|---|---|---|---|---|
| H | M | N | ||
| Urgency | H | 1 | 2 | 3 |
| M | 2 | 3 | 4 | |
| L | 3 | 4 | 5 | |
| Priority Code | Description | Target Response Time | Target Resolution Time |
|---|---|---|---|
| 1 | Critical | Immediate | 1 Hour |
| 2 | High | 10 Minutes | 4 Hours |
| 3 | Medium | 1 Hour | 8 Hours |
| 4 | Low | 4 Hours | 24 Hours |
| 5 | Very low | 1 Day | 1 Week |
Circumstances that warrant the Incident to be treated as a Major Incident
Major Incidents call for the establishment of a Major Incident Team and are managed through the Handling of Major Incidents process.
Indicators
The above prioritization scheme notwithstanding, it is often appropriate to define additional, readily understandable indicators for identifying Major Incidents (see also the comments below on identifying Major Incidents). Examples for such indicators are:
- Certain (groups of) business-critical services, applications or infrastructure components are unavailable and the estimated time for recovery is unknown or exceedingly long (specify services, applications or infrastructure components)
- Certain (groups of) Vital Business Functions (business-critical processes) are affected and the estimated time for restoring these processes to full operating status is unknown or exceedingly long (specify business-critical processes)
Identifying Major Incidents
It is not easy to give clear guidelines on how to identify major incidents although the 1st Level Support often develops a "sixth sense" for these. It is also probably better to err on the side of caution in this respect.
A Major incidents tend to be characterized by its impact, especially on customers. Consider some examples:
- A high speed network communications link fails and part of or all data communication to and from outside the organization is cut off.
- A website grinds to a halt because of unexpected heavy demand prior to a deadline (for example to reserve tickets or make a legal submission) resulting in large numbers of customers failing to meet that deadline.
- A key business database is found to be corrupted.
- More than one business server is infected by a worm.
- The private and confidential information of a significant number of individuals is accidentally disclosed in a public forum.
Note also that all disasters (covered by the IT Service Continuity Strategy and underpinning ITSCM Plans) are Major Incidents and that smaller incidents that are compounded by errors or inaction can become major incidents.
Major Incidents - Key Characteristics
Some of the key characteristics that make these Major Incidents are:
- The ability of significant numbers of customers and/or key customers to use services or systems is or will be affected.
- The cost to customers and/or the service provider is or will be substantial, both in terms of direct and indirect costs (including consequential loss).
- The reputation of the Service Provider is likely to be damaged.
AND
- The amount of effort and/or time required to manage and resolve the incident is likely to be large and it is very likely that agreed service levels (target resolution times) will be breached.
A Major Incident is also likely to be categorized as a critical or high priority incident.
Notes
Is based on: Template "Incident Prioritization Guideline" from the ITIL Process Map.
By: Stefan Kempter ![]() , IT Process Maps.
, IT Process Maps.
Incident Prioritization Guideline › Urgency › Impact › Priority Classes › Major Incidents
 and ITIL 4")






{kind=link}